
Sampling rate - Another different perspective
- JuanS
- Apr 14, 2020
- 10 min read

Updated: May 19, 2021
Sample rate is one of those contro versial topics that people involved in the audio industry tend to discuss and debate ferociously. In essence, its not a complex topic, but its ramifications are extensive and these tend to be overly complicated. We end to accept premises although we might not be able to prove they do support our preconceptions. As expected, in a discussion as this, the classic Nyquist and Shannon theorem and the ear’s bandwidth make an appearance. Surely, at the point of reading all this, many of you will have strong positions about this topic and maybe you follow strongly a paradigm of how to choose your optimal sample rate for different circumstances. Nonethless, I’d like to share a different perspective that is not intended to make you change your mind, but to appreciate the problem with broader and deeper understanding, to have a more profound understanding of what’s usually known and even be open to the idea that not everything is black or white.
Sampling 101
Conceptually, sampling is not a tough concept to understand. Given a high density of information, we take some examples or representative samples of the population we intend to study to give us an idea of what is the general behavior of said population. The intention of this is to make the information more manageable; however, ideal sampling is characterized by allowing the complete reconstruction of the population’s information only through a limited set of samples which clearly is not something easily achievable.
In audio, due to the continuous nature of analog signals, sampling is essential to allow us the manipulation of the signal in the digital domain. Naturally the most common rule to do this effectively is the Nyquist-Shannon theorem which tells us that in order to do an ideal sampling, the sampled signal must have a spectrum with a bandwidth smaller than half of the sample rate which is, in turn, known as the nyquist frequency (Let me know if there’s interest in the mathematical demonstration and build some intuition behind the proof ;) ). It is interesting to see that sampling a signal is equivalent to multiplying it by a pulse train as shown in the following graph.
Given that the product of signals in the time domain is a convolution of their spectra, the sampled signal has, in fact, infinite spectral replicas. The reconstruction is equally simple as the only thing we have to do is to eliminate the spectral replicas and to achieve this it is sufficient to multiply them by a rectangular spectra as the one shown in the following graph. Given that the product of spectra is a convolution between their time domain definition, the reconstruction can be done in a perfect manner as a convolution between a sinc function with our sampled signal as shown in the following graph.
Given that the previous proposition has been proved mathematically, mast discussions are based on whether the theorem is realizable in practice or on the effects of not complying with its conditions such as aliasing. This last one happens when two sinusoids of different frecuencies, after being sampled, are represented by exactly the same set of points. We say that un became an alias of the other because from the perspective of the digital system, they are indistinguishable. Is natural when we sample a signal that is not correctly band limited given that the spectral expansion produced by the product of the signal with the pulse train will produce superposed spectral replica; however, it is important to see that the aliasing is not a phenomena exclusive to sampling (more on this later). We doubt about the quality of anti-alias filters in our audio interfaces as they either deteriorate our signals or are incapable of correctly band limit our signals. We have doubts, and that is ok!, but there’s an untold story in all this that is rarely presented in these discussions.
What the theorem doesn't say
The sampling theorem says that sampling a limited set of instants we can reconstruct the continuous signal completely. In essence its a recipe for the efficient storage of information; however, the sampling theorem doesn’t promise anything about what happens when we modify the signals in the digital domain. Moreover, although this set of samples will be able to fully rebuild the signal, that doesn’t mean that they will be a good representation of the waveform of the analog signal that they represent. The following two graphs show a pair of digital signals. Lets try to predict the analog waveforms that they represent.
Were our expectations matched? That is exactly why the theorem works, because even though there are infinite ways to connect these samples, there’s one and only one combination of sinusoidal frequencies smaller than the Nyquist frequency that connect all these dots. In fact, connecting them in any other way would imply a non band-limited signal at the Nyquist frequency. (Check that technically speaking this also allows the sampling of band-limited signals whose spectra is not necessarily at base band, between -fs/2 and fs/2)
A different perspective
Now that we have enough tools, I’d like to share a different perspective. Digital systems and in general programming languages rarely have a defined and concrete understanding of time. Due to this they don’t really have a notion of frequency (whose units are reciprocal time 1/s). Because of this, they trust us to correctly indicate the used sample rate to appropriately scale all their algorithmic machinery to produce a sensible result in the analog domain. The sample rate, from the digital perspective, is what tells the computer how fast to reproduce information when we want to listen, to know how many samples to generate if we require a precise length of material or how much a signal needs to be “extended" to simulate a reverberation of defined length. In essence this parameter interacts with each and everyone of our processors and forces it to reinterpret what it means to have a sample after sample to produce the same temporal result.
For example, one cycle of a 441Hz sinusoid looks identical to one cycle of 480Hz when the first is produced by a system running at 44.1 kHz and the second one with a system whose sample rate is 48kHz
Naturally, this lead us to the idea that a notch filter at 441Hz at a sampling rate of 44.1kHz is exactly the same algorithm as the same type of filter at 480Hz at a sample rate of 48kHz and accordingly, filtering 480Hz is different at 44.1kHz than at 48kHz. Every single one of our algorithms, each plugin, each fade, each automation, each manipulation of the signal that uses the definition of time or frequency will change its behavior when we change the sample rate, and although in most cases the results might be identical, It is surprising that the cases where this doesn’t hold are relatively unknown.
Digital Aliasing
A common error is to think that aliasing is colateral damage from digitization but in reality is characteristic of any discrete system. It occurs when the spectrum expands beyond the bandwidth delimited by the Nyquist frequency. Due to this, any non linear process (whose essential characteristic, in this case, is that it produces more spectral content than that of the signal before said process) can, potentially, generate aliasing. Given that aliasing is directly related to the Nyquist frequency the behavior of these processors can change drastically when changing the sample rate.
The easiest way to show this is the use of a non-linear time invariant distortion process such as squaring a signal. This process is particularly easy to understand both in the time domain as in the frequency domain serving perfectly to this purpose. Squaring a signal is in essence multiplying it by itself so in the frequency domain it becomes equivalent to a self-convolution (a convolution of its spectrum with itself).
Additionally, due to trigonometrical identities we know that cos(x)^2) = (1 + cos(2x))/2, so we know that at the most the highest frequency will be twice the highest existing frequency.
If this new spectral content were to fall above the Nyquist frequency we would say that it would become an alias frequency of one below said limit. The following graph shows this process.
Naturally, this is not the ideal behavior so the implementation of some form of internal oversampling is common. Nonetheless, this comes at a computational cost y other affections over the signal that is worth considering. Oversampling implies the use of additional anti-alias filters that increase the complexity of the process and open the door to a new set of problems. What filters to use?, How will they affect the phase? How will they modify latency? Are each and all of the steps implemented correctly?
The following graphs show a sine sweep in a distortion processor at three different sample rates.





Additionally, the following audio files show that this is not an imperceptible difference.
Finally, do not think that this is uncommon or exclusive to distortion. Although, certainly distortion is the case where it is harder to control due to the aggressive spectral expansion. Consider also that a manufacturer might favor simplicity of design to obtain a processor with less latency and make it usable in the context of recording (E.g. guitar distortion simulators) and because of this, maybe, even understanding all the implications they might opt for accepting more aliasing in favor of a more usable product in a recording session for example.
Deformación del eje de frecuencias en filtros IIR.
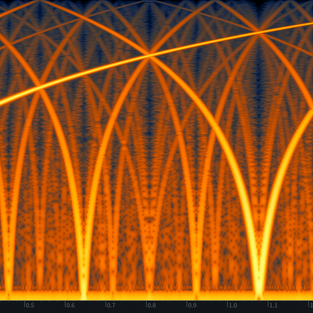
Analog IIR (Infinite impulse response) filters ate based on the direct and feedback summation of different derivatives of signal. Nonetheless, in the digital domain, derivates, and in general anything related to calculus and the use of the concept of the infinitesimal is restricted by the sample rate. For a low frequency taking the slope between contiguous samples in a signal might work as the rate of change of the signal is low, but at high frequencies the separation between samples (the sampling period) together with the frequency of the signal won’t allow a good approximation of the slope of the signal at that point. Because of this, the digitization fo an analog filter will have certain complications that might be affected by the sample rate. Although there are numerical methods as Eulers method to calculate derivatives, and these are used to digitize certain processes, the most common method to perform this task is the bilinear transform or Tunstin’s Method or Trapezoidal Method (Let me know If there’s some interest in checking this topic in detail). Conceptually, it allows the conversion of the transfer function of an analog filter into a digital one with advantages as the preservation of the filter order and the preservation of the complexity in its zero-pole representation as well as the certainty of obtaining a stable digital filter (Note that any system that uses feedback could become unstable under certain conditions). To achieve this it takes the analog frequency axis, which is essentially infinite, and contracts it into the frequency range between 0 and fs/2. Of course this will produce a warping of the digital frequencies! Due to this the bilinear transform gives us an additional parameter to be able to match one and only one analog frequency to one digital frequency. Usually this last parameter is used to obtain exactly the same phase an magnitude between the analog and digital filters at the central frequency of the filter, but this leaves all the other frequencies vulnerable to the effects of the deformation. The following graph shows how this frequency axis deformation happens.
This graph shows multiple examples of digital filters created with bilinear transforms together with its analog counterparts to show how the frequency warping affects their transfer functions.
Check that the warping has a notable effect only at high frequencies and in closer proximity to the Nyquist frequency, so it Isi logical to think tha the effect of this deformation will be less noticeable at higher sample rates. For example, a parametric filter at 10kHz will have the same frequency warping at 48kHz that a filter at 20kHz when the sampling rate is 96kHz. Again, for the algorithm the sampling frequency represents the speed at which the samples will reproduced, so the relevant part is not the absolute frequency of the filter but its relationship to the sample rate. Actually, because of this most literature on digital filters use a normalized frequency axis where fs corresponds to 1. IN the previous case a filter in 10Khz at a samplerate of 48kHz has a normalized frequency of 0.21Hz/fs just as a filter at 20kHz with a sample rate at 96kHz. This two filters, algorithmically speaking, are not similar but identical!.
It would seem like the solution could be internal oversampling again; however, given that in the case of a linear system there’s no spectral expansion this might be inefficient as no additional spectra is created. Additionally, there are other methods to improve the bilinear transform and obtaining a transfer function in which the behavior fo the frequency warping si appropriate (In fact I wrote a paper tackling this exact problem with, as expected, a diferente perspective ;) ).
Some final ideas
Digital signal processing is an incredibly rich field where each of them have its own problems and solutions, but in each case, the sample rates is a variable that without a double might affect the behavior of the algorithms. I wanted to share two problems that I consider relatively easy to understand and that simultaneously have a significant impact on the practical reality of audio so it is possible to produce evidence related to them. However, you must know that there’s a ton of other cases! The variability of the length of FIR filters and how this affects latency, the dependency of the precision of recursive (IIR) filters with the sample rate, the variability of the behavior of filters inside reverberations, flangers and phasers, the precision in the measurements related to the waveform, intermodulation biproductos of inaudible content and many more, ALL related and affected by sample rate. Certainly there are interesting conversations in relationship to the quality of anti-aliasing filters in ADCs (analog To digital converters) but with everything that happens in the digital world not explained by the Nyquist-shannon theorem, do we really think that said theorem should be the only argument when discussing what is the sample rate?
Personally, I think that I’ve switched sides regarding this as many times as possible. I started holding on to certain ideas but as I studied more I ended up reevaluating my own thoughts and switching sides. Studied some more and switched once again, and with each piece of knowledge I realized something that I’d consider applicable to any similar situation: When something causes so much controversy the most illogical position is to believe that the answer is evident. Certainly, it is easy to find people of great experience and knowledge in both sides of the discussion. 44.1 vs 192kHz is something that certainly can’t be reduced to a no-brainer. There are so many details into all this that it is hard to argue that my position or any position is obviously superior. Having said this, what do you think?


Comments